线上故障处理指南
一、最重要的三件事
1、止损
2、止损
3、止损
故障损失≈单位时间内的损失*故障时长
尽快恢复,是止损的最佳办法,至于查找根本原因,或者从根本上解决问题,那是服务恢复可用后的事情
二、故障处理三板斧
由于止损>解决根本问题,所以当故障来了,简单粗暴的三板斧往往是止损行之有效的手段
1、重启
如果是单个或多个机器上的服务出现响应问题,先重启就能先恢复,能恢复就能止损
2、回滚
如果是发布后产生的问题,除非可以确认跟故障毫不相关,不然回滚就是最好的选择,回滚不一定能恢复,但是能减少变量,有利于更快定位问题,止损
3、扩容
请求数、CPU/内存使用率、网卡出入流量,这些参数能快速定位服务是否受到了更大压力,如果有,立即扩容就是最佳选择
如果经过一系列初步判断都不能确认问题原因,扩容也可能是尽快止损的最佳选择
三、资损故障处理
资金直接损失问题相较于一般问题影响更大,处理起来也更棘手,三板斧中只有回滚能应对资损问题,所以这里单独列举资损问题处理办法
1、持续性发生的资损
例如:话费充值发生满减bug,用户充值任意金额都优惠10元钱,不限次数
解决办法:1关2改3追
关:关掉问题入口(关掉问题服务/关掉问题服务器),然后关闭进行中的任务
改:改掉bug,然后重新打开服务
追:联系用户追回损失(客服/法务)
2、特定条件的资损
例如:话费充值发生满减bug,用户充值>300元时,优惠10元钱,不限次数
这种情况就特别需要平衡了
关入口损失>bug损失:改、追
关入口损失<bug损失:关、改、追
3、关于追
追回损失是权利,但不代表一定要行使权力,也需要平衡
例如:
男子“薅羊毛”将爱奇艺会员充值到2111年,被刑拘 - IT之家
腾讯视频VIP每月仅需0.2元被疯抢,官方称将兑现全部订单_网易新闻
四、故障信息同步
良好信息同步,是快速恢复和止损的重要基础
1、关联方同步
在「故障信息同步群」第一时间同步问题跟进状态,并@上下游负责人知悉
如需上下游协助,建立问题处理沟通群(例如:0707充值优惠问题处理)
紧急问题需要会议沟通恢复办法,使用「作战室」会议室现场沟通,或者在主要影响团队附近开站立会
「故障信息同步群」是为了帮助我们第一时间同步故障信息,信息传递的及时&准确能为故障处理提供好的舆论基础
「作战室」可以帮助故障处理负责人协调各方协同处理故障,提高故障处理效率
2、上级同步
在团队沟通群,第一时间同步直属上级当前问题现象、跟进人、跟进状态、预计恢复时间等信息
例如:
收到话费充值优惠异常反馈,正在确认影响
充值问题已确认,上版本优惠校验代码有bug,XXX正在操作服务回滚,预计5分钟内恢复
五、故障处理流程参考
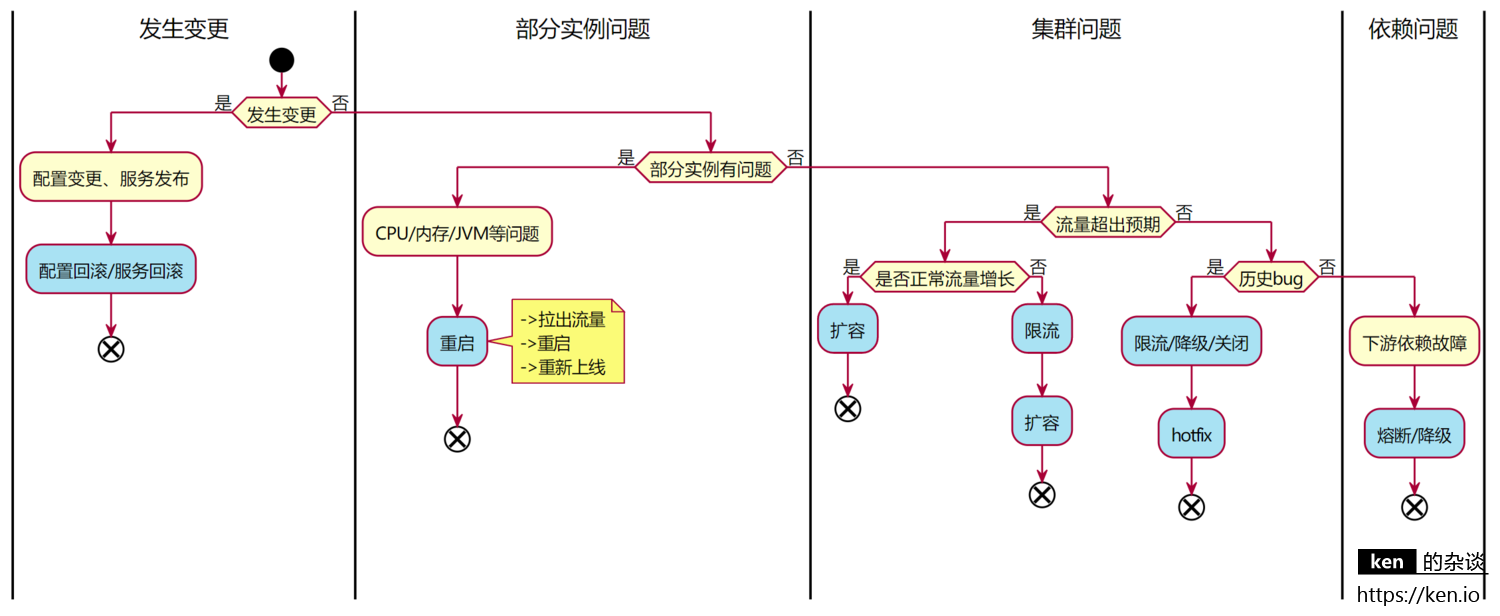
1、变更问题
配置/代码变更后产生的问题,首选回滚,恢复比排查Bug更重要
但一定要确认是否可以回滚,在某些情况下,如果因为问题,用户已经进入了错误的流程,或者说回滚后,用户的数据已经无法兼容(常见于系统重构引起的故障)那么就不建议回滚
从降低维护成本以及提升故障处理效率的角度,理论上所有的上线都应该是可回滚的,如果上线的代码/配置不可回滚,那么说明我们做出了有缺陷的设计,应该加以改进,在技术评审环节排除掉此类问题
2、部分机器问题
如果只是部分机器/实例有异常,那么可以通过Zabbix/Nagios等监控平台提供的信息确认,如果是硬件资源使用过高,重启可能是最快的恢复手段,当然也可能是这部分实例所在的物理机出现了问题,那么就需要运维提供的故障转移手段帮助恢复了
3、集群整体问题
如果是整个集群除了问题,而且是非最近上线代码Bug引起的,那么通常是流量突增引起的,扩容、限流等手段能上就上,如果是触发了某个历史Bug,那就服务降级或者关闭入口,尽快的执行Bug修复工作了
4、下游依赖问题
如果是依赖的下游出现了问题,那么做的就是熔断、降级,然后等待下游恢复
六、总结
线上故障,无论大小都值得我们去总结,总结的内容可以包含且不仅限于:问题现象、影响范围、根本原因、时间线、改进措施等,其中尤其要关注的就是改进措施,一定要可落地执行,能够追踪进展,这样才能真正的帮助我们进步
线上稳定性保障是一个体系,提高交付质量和建立完善的监控等事前工作是我们更应该关注的
最后,祝大家的代码永无Bug~