HBase集群部署指南
一、前言
1、HBase简介
HBase是一个分布式的、面向列的开源数据库。
HBase在Hadoop之上提供了类似于Google Bigtable的能力。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
https://baike.baidu.com/item/HBase
2、HBase应用场景
- 大数据存储:应用日志、用户行为等
- 数据批量运算、分析
二、准备工作
1、集群节点规划
| 机器名 | IP | 节点应用 |
|---|---|---|
| hdfs01 | 192.168.88.91 | Master |
| hdfs02 | 192.168.88.92 | Master-Backup RegionServer |
| hdfs03 | 192.168.88.93 | RegionServer |
| zknode1 | 192.168.88.11 | ZooKeeper |
| zknode2 | 192.168.88.12 | ZooKeeper |
| zknode3 | 192.168.88.13 | ZooKeeper |
2、软件环境说明
| 项 | 说明 |
|---|---|
| Linux Server | CentOS 7 |
| JDK | 1.8.0 |
| ZooKeeper | 3.4.11 |
| NTP | 4.2.6 |
| Hadoop | 3.0.0 |
| HBase | 1.4.2 |
3、基础环境准备
- CentOS7虚拟机安装
Hyper-V下安装CentOSx虚拟机:https://ken.io/note/hyper-v-course-setup-centos
参考以上文章部署6台CentOS虚拟机
- JDK1.8部署
CentOS下JDK部署:https://ken.io/note/centos-java-setup
参考以上文章为每台虚拟机部署JDK8
4、ZooKeeper集群部署
- 为什么要部署ZooKeeper
可以通过ZooKeeper完成Hadoop NameNode的监控,发生故障时做到自动切换,从而达到高可用
- 部署指引&要求
基于CentOS7部署ZooKeeper集群:https://ken.io/note/zookeeper-cluster-deploy-guide
参考以上文章在以下节点部署ZooKeeper集群
| 机器名 | IP | 节点应用 |
|---|---|---|
| zknode1 | 192.168.88.11 | ZooKeeper |
| zknode2 | 192.168.88.12 | ZooKeeper |
| zknode3 | 192.168.88.13 | ZooKeeper |
5、HBase节点系统设置调整
本小结配置只针对HBase节点
- 机器名修改
#hdfs01
hostnamectl set-hostname hdfs01.hdfscluster
#hdfs02
hostnamectl set-hostname hdfs02.hdfscluster
#hdfs03
hostnamectl set-hostname hdfs03.hdfscluster
参考:https://ken.io/note/centos-hostname-setup
- 配置hosts
#修改hosts文件
vi /etc/hosts
#增加以下配置
192.168.88.91 hdfs01 hdfs01.hdfscluster
192.168.88.92 hdfs02 hdfs02.hdfscluster
192.168.88.93 hdfs03 hdfs03.hdfscluster
- 关闭防火墙
#关闭防火墙
systemctl stop firewalld
#禁用防火墙开机启动
systemctl disable firewalld
- 修改ulimit
在Apache HBase官网的介绍中有提到,使用 HBase 推荐修改ulimit,以增加同时打开文件的数量,推荐 nofile 至少 10,000 但最好 10,240 (It is recommended to raise the ulimit to at least 10,000, but more likely 10,240, because the value is usually expressed in multiples of 1024.)
修改 /etc/security/limits.conf 文件,在最后加上nofile(文件数量)、nproc(进程数量)属性,如下:
#修改文件
vi /etc/security/limits.conf
#追加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
- 关闭SELinux
因为 Hadoop、HBase 的启动需要使用 SSH,如果 SELinux 处于开启状态,默认情况下无法完成SSH的免密登录。最简单的做法就是关闭SELinux
#1、关闭SELinux:
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
#2、重启:
reboot
6、HBase节点时间同步
如果服务器节点之间时间不一致,可能会引发HBase的异常,所以我们需要通过NTP的手段保证HBase各节点的时间是同步的。
参考以下文章,对HBase节点进行NTP部署
NTP服务器部署以及时间同步:https://ken.io/note/ntp-server-deploy-time-sync
- hdfs01节点部署NTP服务与公共NTP服务器进行时间同步
- hdfs02、hdfs03节点部署NTP服务与本地NTP服务器(hdfs01)进行时间同步
7、HBase节点SSH免密登录准备
Hadoop、HBase 的启动需要使用 SSH免密登录
- 在Master节点生成密钥
通过ssh-keygen -t rsa命令生成密钥,一直回车即可
(此操作在hdfs01节点进行)
#生成密钥
ssh-keygen -t rsa
#查看公钥内容
cat ~/.ssh/id_rsa.pub
- Master到Slave的SSH无密码登录
在Slave节点创建~/.ssh/authorized_keys文件
并将Master节点~/.ssh/id_rsa.pub中的内容写入保存
在hdfs02、hdfs03节点进行如下操作cd
#创建ssh文件夹
mkdir ~/.ssh
#创建ssh授权密钥文件
vi ~/.ssh/authorized_keys
#写入Master节点~/.ssh/id_rsa.pub中的内容
- SSH免密登录测试
[root@hdfs01 ~]# ssh 192.168.88.92
The authenticity of host '192.168.88.92 (192.168.88.92)' can't be established.
ECDSA key fingerprint is 59:12:85:3f:ed:67:2c:09:e4:61:25:1c:d8:d4:e5:fd.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.88.92' (ECDSA) to the list of known hosts.
Last login: Mon Mar 12 18:18:16 2018 from 192.168.88.1
[root@hdfs02 ~]#
#退出登录
logout
8、Hadoop集群部署
- 为什么要部署Hadoop?
因为HBase是基于Hadoop的应用
- 部署指引&要求
基于CentOS7部署Hadoop集群:https://ken.io/note/hadoop-cluster-deploy-guide
参考以上文章在以下节点部署Hadoop集群
| 机器名 | IP | 节点应用 |
|---|---|---|
| hdfs01 | 192.168.88.91 | NameNode等 |
| hdfs02 | 192.168.88.92 | DataNode等 |
| hdfs03 | 192.168.88.93 | DataNode等 |
三、HBase集群部署
1、下载软件包&部署准备
- 下载最新版HBase
官方HBase镜像包下载地址:http://mirrors.hust.edu.cn/apache/hbase
本次我们选用的是HBase 1.4.2版本
#进入下载目录
cd /home/download
#下载Hadoop
wget http://mirrors.hust.edu.cn/apache/hbase/1.4.2/hbase-1.4.2-bin.tar.gz
#解压到指定目录
mkdir /usr/hdfs
tar -zvxf hbase-1.4.2-bin.tar.gz -C /usr/hdfs/
2、修改HBase配置
- 配置Hadoop环境变量
#修改环境变量
vi /etc/profile
#增加以下内容
export HBASE_HOME=/usr/hdfs/hbase-1.4.2
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
source /etc/profile
HBase的配置文件位于/usr/hdfs/hbase-1.4.2/conf下。
既然我们已经配置了环境变量,后续均已$HBASE_HOME替代/usr/hdfs/hbase-1.4.2
- 复制hdfs-site.xml配置文件
复制$HADOOP_HOME/etc/hadoop/hdfs-site.xml到$HBASE_HOME/conf目录下,这样以保证hdfs与hbase两边一致,这也是官网所推荐的方式。在官网中提到一个例子,例如hdfs中配置的副本数量为5,而默认为3,如果没有将最新的hdfs-site.xml复制到$HBASE_HOME/conf目录下,则hbase将会按3份备份,从而两边不一致,导致会出现异常。
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HBASE_HOME/conf/
- 配置hbase-site.xml
修改配置文件:
vi $HBASE_HOME/conf/hbase-site.xml
更改为以下配置
<configuration>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.88.11,192.168.88.12,192.168.88.13</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/zookeeper/data</value>
<description>
注意这里的zookeeper数据目录与hadoop ha的共用,也即要与 zoo.cfg 中配置的一致
Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdfs01:9000/hbase</value>
<description>
The directory shared by RegionServers.
官网多次强调这个目录不要预先创建,hbase会自行创建,否则会做迁移操作,引发错误
至于端口,有些是8020,有些是9000,看 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 里面的配置,本实验配置的是
dfs.namenode.rpc-address.hdfscluster.nn1 , dfs.namenode.rpc-address.hdfscluster.nn2
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>
分布式集群配置,这里要设置为true,如果是单节点的,则设置为false
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description>
</property>
</configuration>
- 配置regionserver文件
编辑 $HBASE_HOME/conf/regionservers 文件,输入要运行 regionserver 的主机名
#编辑文件
vi $HBASE_HOME/conf/regionservers
#写入以下内容
hdfs02
hdfs03
- 配置 backup-masters 文件(master备用节点)
HBase 支持运行多个 master 节点,但只能有一个活动节点(active master),其余为备用节点(backup master),编辑 $HBASE_HOME/conf/backup-masters 文件进行配置备用管理节点的主机名
#编辑文件
vi $HBASE_HOME/conf/backup-masters
#写入以下内容
hdfs02
- 配置 hbase-env.sh 文件
由于本次部署使用的是独立ZooKeeper,所以需要关闭内置的
另外,HBase主节点通过ssh免密登录到其他节点启动HBase的时候,/etc/profile是不生效的
所以要单独配置JAVA_HOME环境变量,不然启动HBase的时候,会提示:
Error: JAVA_HOME is not set
#编辑文件
vi $HBASE_HOME/conf/hbase-env.sh
#配置JDK环境变量(JAVA_HOME)
export JAVA_HOME=/usr/java/jdk1.8.0_161
#修改配置(文件尾部)
export HBASE_MANAGES_ZK=false
3、启动HBase
在此之前确保Zookeeper、Hadoop集群均已启动
以下启动方式任选一种
- 便捷启动(推荐)
$HBASE_HOME/bin/start-hbase.sh
- 分步启动
#启动hbase master(hdfs01)
hbase-daemon.sh start master
#启动hbase regionserver(hdfs02、hdfs03)
hbase-daemon.sh start regionserver
#启动hbase backup-master(hdfs02)
hbase-daemon.sh start master --backup
四、HBase集群测试
1、HBase Shell命令测试
- 进入Shell命令行
[root@hdfs01 ~]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdfs/hbase-1.4.2/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdfs/hadoop-3.0.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
Version 1.4.2, rb4ec89059cc3a7416c2012bb1a9d31f1cd34b78c, Wed Feb 21 14:25:53 PST 2018
hbase(main):001:0>
- 查看集群节点信息
hbase(main):001:0> status
1 active master, 1 backup masters, 2 servers, 0 dead, 1.0000 average load
- 创建表
HBase创建表语法:
create [tablename],[column01],[column02],[column] ……
hbase(main):002:0> create "test","col1","col2"
0 row(s) in 2.5870 seconds
- 查看表
hbase(main):003:0> list "test"
TABLE
test
1 row(s) in 0.0060 seconds
- 导入数据
HBase表导入数据语法:
put [tablename],[rowname],[column],[colnumValue]
put [tablename],[rowname],[column:subColumn],[colnumValue]
导入数据示例:
#导入指定行列数据
put "test","row1","col1","row1_c1_value"
#导入指定行列以及子列数据
put "test","row2","col1:s1","row1_c2_s1_value"
put "test","row2","col1:s2","row1_c2_s2_value"
- 全表扫描数据
hbase(main):006:0> scan "test"
ROW COLUMN+CELL
row1 column=col1:, timestamp=1520935981966, value=row1_c1_value
row2 column=col1:s1, timestamp=1520936007587, value=row1_c2_s1_value
row2 column=col1:s2, timestamp=1520936023896, value=row1_c2_s2_value
2 row(s) in 0.1430 seconds
- 条件查询
#查询row1数据
get "test","row1"
- 禁用/启用表
#禁用表
disable "test"
#启用表
enable "test"
- 删除表
#删除表
drop "test"
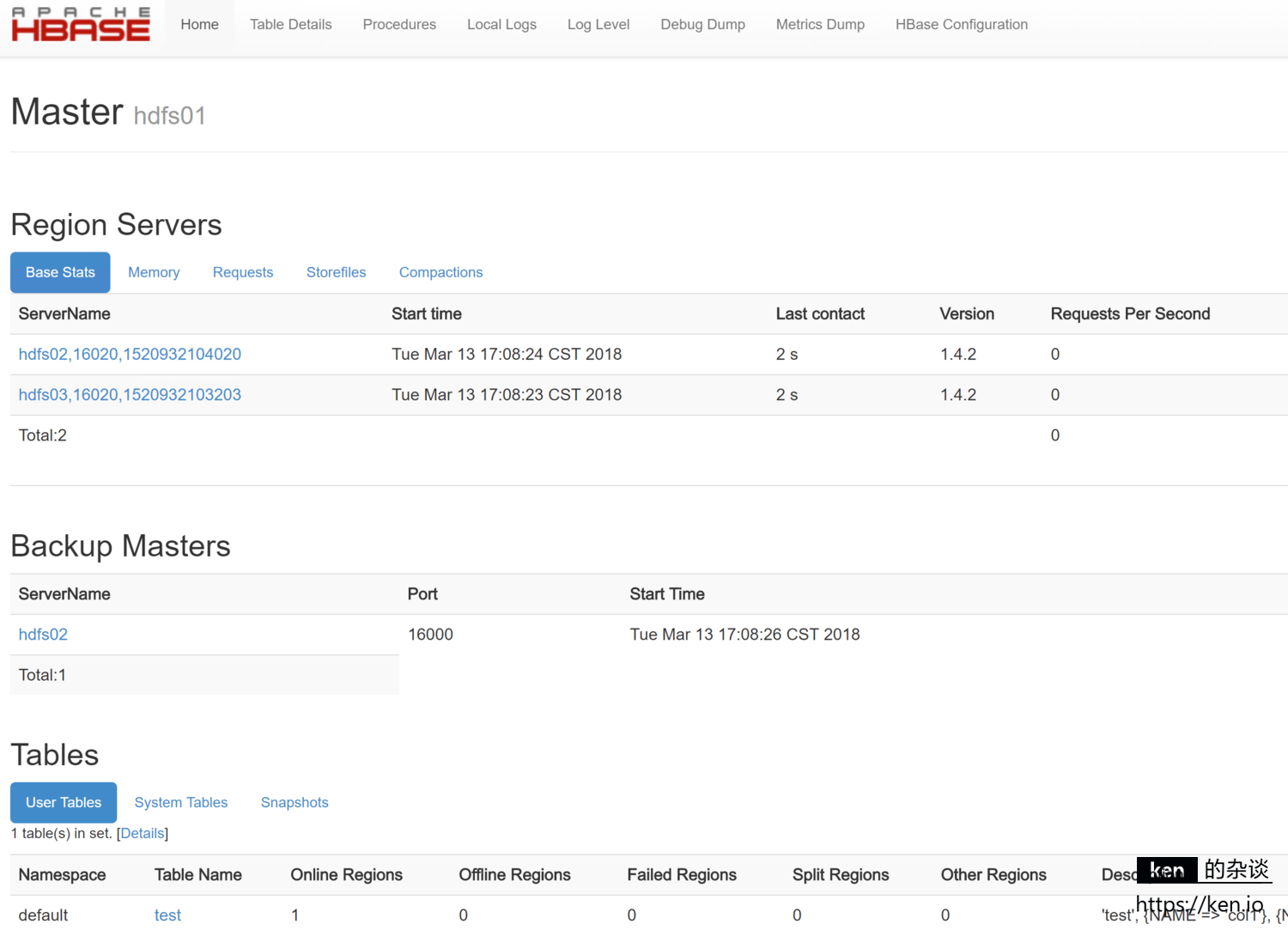
2、Web管理页面
HBase提供了Web管理界面,浏览器输入HMaster节点IP:16010即可:
http://192.168.88.91:16010
- 集群状态
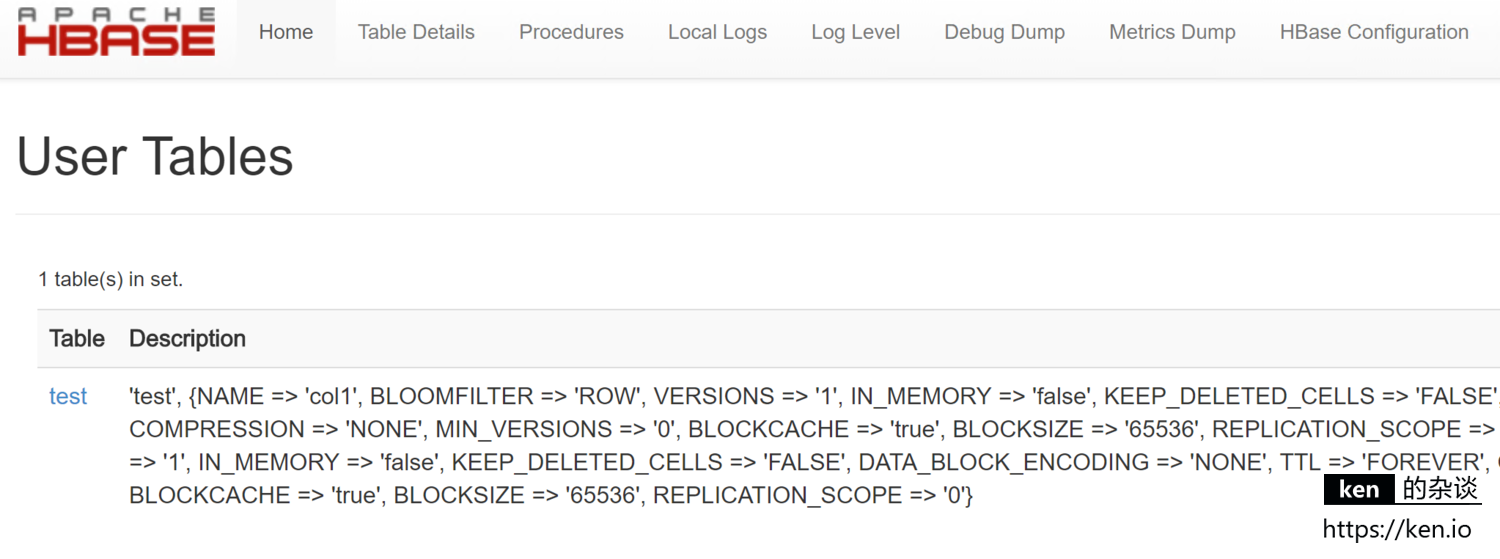
- 表详细信息
在Tables这一栏,点击[Details]超链接,即可查看所有表的详细信息
也可以通过URL直接访问:http://192.168.88.91:16010/tablesDetailed.jsp
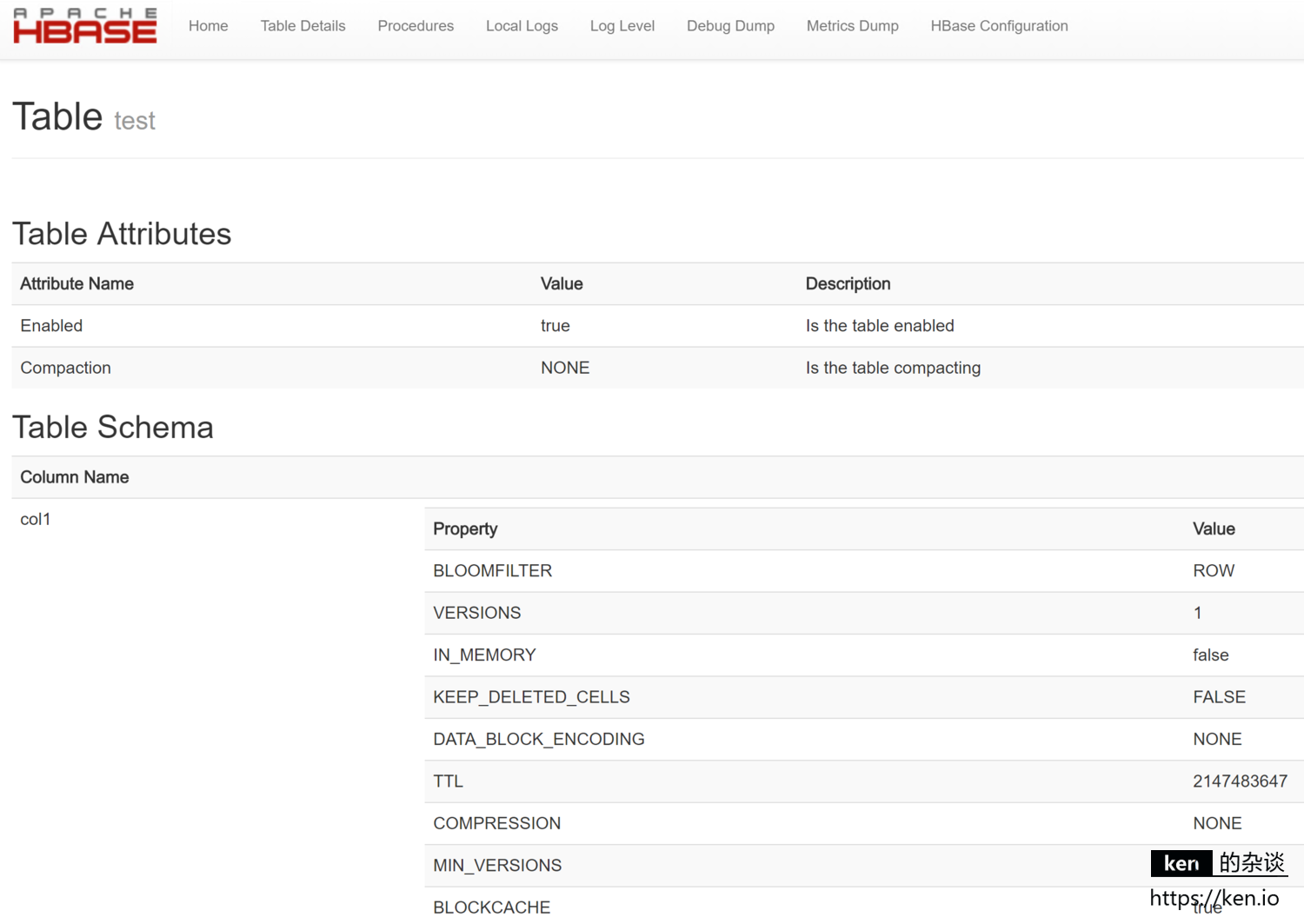
- 表属性、Schema
在Tables这一栏,点击表名的连接,即可查看该表的信息/属性
也可以通过URL直接访问:http://192.168.88.91:16010/table.jsp?name=test
其他功能,自行试用,这里 ken.io 就不一一列举了